Don’t be confused by the title of this post - I will tell you about my experience in the development of xmpp client xi. The first version of this client was written in Haskell in the shortest time (for me, of cource), and this fact provides the second emotional part of title =)
First of all - xi was inspired by ii irc client. It explains the all of its features, design and main idea. In short - after this post I’m a huge fan of this tool and philosophy.
Second - xi was written in Haskell. I will not explain why =)
Now let’s take a look inside. We can see a lot of dependencies of course - xi uses pontarius xmpp for the XMPP interaction. But there is an interesting hidden trick - we must use this library from the github directly yet, because of an unpleasant bug. This can be done by the cabal sandbox add-source command:
Other important feature is the listening of the file, which will contain a user input. We will use a fsnotify library for these purposes. Michael Snoyman shared the implementation of this feature (he always flying to help, when SO question contains the haskell and conduit keywords =). The main idea is the monitoring file changes by fsnotify, and save the current position in file. There are several disadvanteges with this approach - e.g. we can’t handle a file truncation. But for our purposes we can use files, that will never be truncated.
get a user roster and convert it to the internal representation (the ContactList type)
create an appropriate directory structure (a separate directory for each contact with in/out)
for the each input file start a separate thread to monitoring the user input
start a thread for monitoring the incoming messages
Little bit about client details. A Session and ContactList objects have been shared through the Reader monad. For the parsing of configuration file yaml-config library has been used. Also, there is an ability to see an entire xmpp data flow - this requires only the debug mode in configuration.
Client source code hosted on the github, but you should keep in mind, that it’s more prototype, than a completed project. So if you want to improve something - welcome =)
It can be working, until you don’t use pgbouncer. This option hasn’t supported because of the connection pool - when you close a connection with search_path, it will be returned into the pool, and can be reused with the out of date search_path.
So what we gonna do? The only choice is to use connection_create signal:
But where should we place this code? In general case if we want to handle the migrations, the only place is a settings file (a model.py isn’t suitable for this, when we want to distribute an application models and third-party models over different schemas). And to avoid circular dependencies, we should use three (OMG!) configuration files - default.py (main configuration), local.py/staging.py/production.py (depends on the server), migration.py (used to set a search path). The last configuration is used only for the migration purposes:
For the normal usage we can connect set_search_path function to the connection_create signal in the root urls.py and avoid the migration.py configuration of course.
But that’s not all - there is one more trouble with the different schemas, if you using TransactionTestCase for testing. Sometimes you can see an error at the tests tear_down:
Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.
It seems like there is no good IRC plugin for vim - I found none of them at least. But there is a brilliant geeky alternative - ii. Here is a quote from its site:
ii is a minimalist FIFO and filesystem-based IRC client. It creates an irc directory tree with server, channel and nick name directories. In every directory a FIFO in file and a normal out file is created.
The in file is used to communicate with the servers and the out files contain the server messages. For every channel and every nick name there are related in and out files created. This allows IRC communication from command line and adheres to the Unix philosophy.
To configure the IRC workflow (join, identify, read/write) you can use theseposts. Here I want to help you avoid several caveats.
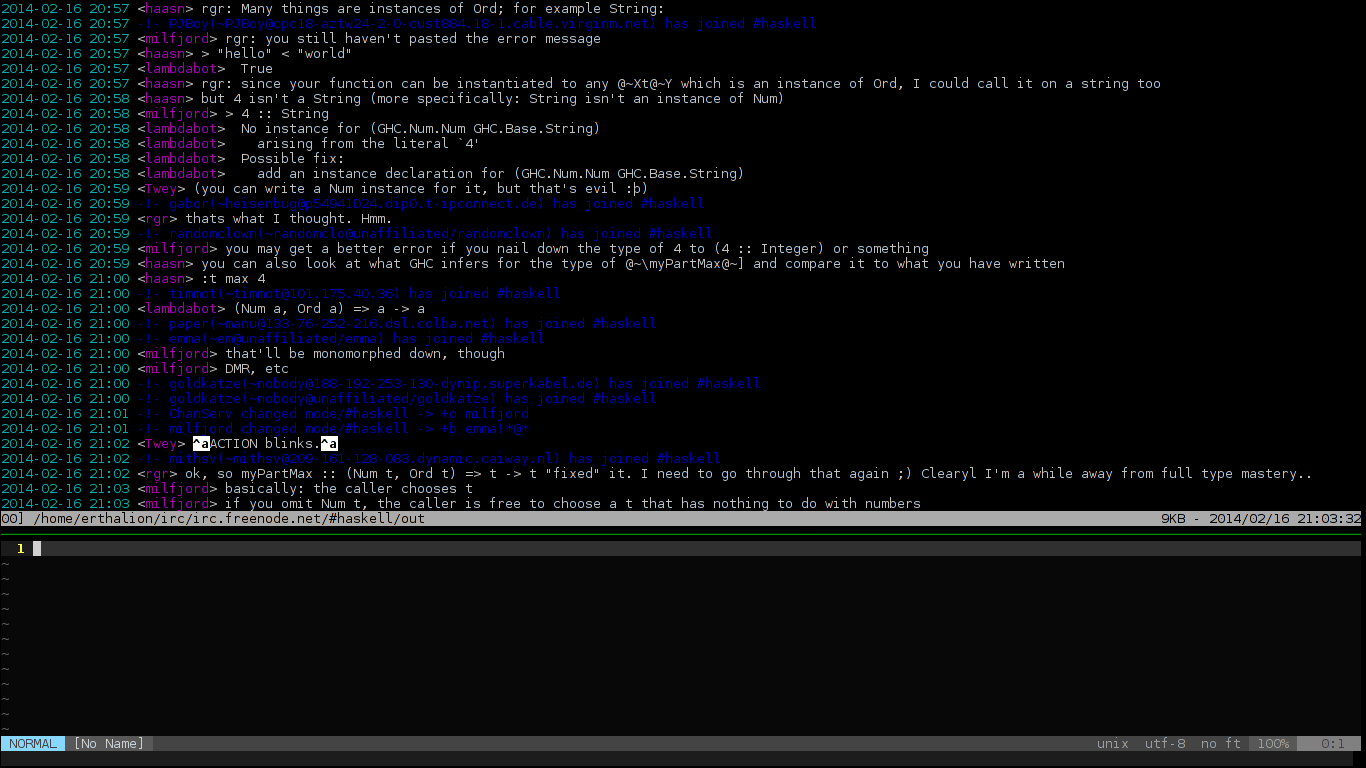
First of all, there is the final result you’ll get:
We should use -2 option for tmux to force 256 colors, and -cS ii option for multitail to ii syntax highlighting. After all this we can execute ./tmux_open.sh channel command to open a two pane, that will contain IRC channel log and vim ifself.
To type in IRC session we will use vim with the following mappings:
Some time ago I was faced with the need to implement the sharding in Django 1.6 . It was an attempt to make step beyond the standart features of this framework and I felt the resistance of Django =) I’ll talk a bit about this challenge and its results.
Let’s start with definitions. Wikipedia says that:
A database shard is a horizontal partition in a database.
Horizontal partitioning is a database design principle whereby rows of a database table are held separately, rather than being split into columns (which is what normalization and vertical partitioning do, to differing extents). Each partition forms part of a shard, which may in turn be located on a separate database server or physical location.
We wanted split our database entities by the different PostgreSQL schemas and used something like this for the id generation. The sharding model was clear, but how to implement it in the Django application?
My solution of this problem was a custom database backend, that contains a custom sql compilers. Maybe it was a dirty hack, but I hope it wasn’t =)
To create your own custom database backend, you can copy structure from one of the existing backends from django.db.backends (postgresql_psycopg2 for our case) and override DatabaseOperations:
A custom sql compilers will be adding a corresponding schema name into the sql request based on the entity id:
# compilers.py
classCustomSQLCompiler(SQLCompiler):defas_sql(self):table=self.query.get_meta().db_tableiftablenotinself.sharded_tables:returnsuper(CustomSQLCompiler,self).as_sql()else:sql,params=super(CustomSQLCompiler,self).as_sql()""" The first item of the params tuple must be entity id
"""schema=self.get_shard_name(params[0])old='"{}"'.format(table)new='{}."{}"'.format(schema,table)sql=sql.replace(old,new)returnsql,paramsSQLCompiler=CustomSQLCompiler
That’s all! Oh, okay, that’s not all =) Now you must create a custom QuerySet (with the two overrided methods - get & create) to provide a correct sharded id for an all entities.
But there is one problem - migrations. You can’t migrate correctly your sharded models and it’s sad. To avoid this we inctoruced the some more complex database configuration dictionary. We used the special method, that converted this complex config into the standard with a lot of database connections - a one for each shard. All connections have the search_path option. In the settings.py we must take in account a type of action:
# settings.py
defget_shard_settings(shard_migrate=False,shard_sync=False):""" Not an all apps must be sharded.
"""installed_apps=('some_sharded_app1','some_sharder_app2',)databases=DB_CONFIGURATOR(DB_CONFIG,shard_migrate=shard_migrate,shard_sync=shard_sync)returninstalled_apps,databases""" We must separate
- normal usage,
- sharded models synchronization
- sharded models migration
"""ifsys.argv[-1]=='shard_migrate':delsys.argv[-1]INSTALLED_APPS,DATABASES=get_shard_settings(shard_migrate=True)elifsys.argv[-1]=='shard_sync':delsys.argv[-1]INSTALLED_APPS,DATABASES=get_shard_settings(shard_sync=True)else:DATABASES=DB_CONFIGURATOR(DB_CONFIG)
Now we can manage sharded migrations by --database options. For convenience you can write a fab script of course.
And one more and last caveat - you must create SOUTH_DATABASE_ADAPTERS variable, that will be pointing to original postgres adapter south.db.postgresql_psycopg2 - south can’t create a correct migration otherwise.