Query optimizer and chess?
07 Aug 2020Do not be afraid, this short blog post is about databases and does not contain any unreasonable metaphysical references. In fact, it’s a result of a journey through couple of whitepapers and books with an unexpected intersection of two rather different fields. I will try to describe everything step by step, so that we can see if chess has anything in common with database query optimizer.
Database query optimizer
Let’s prepare some background and definitions. PostgreSQL documentation says:
The task of the planner/optimizer is to create an optimal execution plan. A given SQL query (and hence, a query tree) can be actually executed in a wide variety of different ways, each of which will produce the same set of results. If it is computationally feasible, the query optimizer will examine each of these possible execution plans, ultimately selecting the execution plan that is expected to run the fastest.
And later in the optimizer readme:
During the planning/optimizing process, we build “Path” trees representing the different ways of doing a query. We select the cheapest Path that generates the desired relation and turn it into a Plan to pass to the executor.
So, the optimizer prepares an optimal way to execute a query and represent it in the form of Path trees. Everything sounds clear and simple. Except that it isn’t, mostly thanks to cardinality estimation despite years of progress. As an example one can find couple of works from the past, when a common observation about PostgreSQL is that cardinality under-estimates sometimes make optimizer to select nested-loop joins even when other join methods could be more efficient (it would be interesting to check if it’s still a thing).
Everyone can learn
Unless you’ve spent last several years in an underground bunker you probably have noticed raise of interest to machine learning as well as its applications. Databases are also not an exception, in the last couple of years we see a lot of whitepapers and projects devoted to leverage various machine learning techniques to improve databases performance, e.g. Neo (which is in fact the main source of inspiration for this blogpost) or Adaptive query optimization for PostgreSQL. For me, as an amateur in machine learning, the idea sounds approximately like “lets make optimizer to learn from its own mistakes”. Surprisingly this idea is not exactly new, LEO DB2’s learning optimizer was suggested already in 2001, although of course a lot of progress has being done since then. Let’s see in more details how it works based on Neo example:
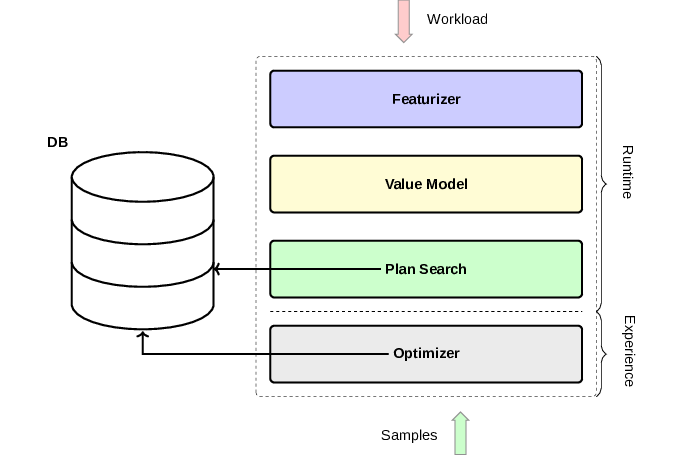
-
First Neo collects expertise based on the sample workload and hints from a normal database query optimizer. It is important to provide an expert knowledge, since otherwise learning time will be too big for any practical usage.
-
Based on collected expertise a deep neural network (called “Value Model”) is trained. The purpose of this neural network is to predict the final execution time of any given query execution plan.
-
For any real incoming query it’s being transformed into a set of features that represent e.g. join order.
-
Having a set of features and “Value Model” at hands Neo performs best-first search of the plan space for the most efficient plan suitable for the query.
Essentially the algorithm takes an existing expertise and learn to predict how good or bad an execution plan would be. Then for every query it performs a non-exhaustive search in the plan space guided by learned experience. Sounds interesting, but what does it have to do with chess again?
Games
The book “The art of doing science and engineering” mentions an interesting example of self-learning programms. It was a checker playing program developed by Arthur Samuel with an interesting idea. In the core of the program was a scoring function for measuring the chances of winning. To improve this function Samuel made the program play thousands of games against itself to tune formula parameters.
This book was originally published in 1996, and Richard Hamming mentioned that AI and self-learning algorithms is a topic one cannot afford to ignore. In 1997 in the second match of six games a reigning world chess champion Garry Kasparov was defeated by a supercomputer Deep Blue under tournament conditions for the first time in the history.
What seemed to be an end of chess as we know them was once again changed in 2017, when DeepMind team released a preprint introducing another chess algorithm AlphaZero. Interestingly this work did not bring more misery for human chess players, but rather some signs of hope. The reason for that is the style of AlphaZero, much more human like and creative than anything before. For example the book “Game changer: AlphaZero’s Groundbreaking Chess Strategies and the Promise of AI” contains this beautiful game:
What is interesting about this game is that the position after White’s 20th move repeats another brilliant game after White’s 21st move. But the latter one was played by human players, namely Gata Kamsky and Yasser Seirawan in 2012 in US Championship!
Why was it so important and what is the difference between AlpaZero and any other chess engine?
Well, usually engines like e.g. Stockfish evaluate positions on a chess board using features provided by human players and carefully tuned weights. They’re combined with a high-performance alpha-beta search that expands a search tree using numerous clever heuristics and domain-specific adaptations to provide the final result.
AlphaZero uses another approach and utilizes a deep value network, which takes a board position and move probabilities to evaluate how good or bad this position is. All the values and probabilities are learned by AlphaZero from self play, as there is no provided heuristic or any human knowledge except the game rules. The resulting neural network is being used to guide the search for a next move using Monte-Carlo tree search (interesting enough, it could be also improved via model-free policy-optimization algorithm). Does it sound familiar?
Pulling bits together
Indeed, the similarity between what we have seen in Neo and AlphaZero is so striking that the authors of former mentioned “the architecture of Neo closely mirrors that of AlphaGo”, where AlphaZero could be considered as a more generalized variant of the AlphaGo. And it’s should not be surprising, since both query optimization and chess share the same idea of searching for the optimal solution based on the existing experience! Probably one could even speculate that the same approach could be used in other fields to solve similar problems.
This sounds very exciting, but as always there are couple of concerns that need to be addressed:
-
Learning techniques can outperform other approaches in average case, but fail miserably in the worst cases (tail performance). This could be true even for AlphaZero, but in a different form. It had learned everything without an opening books, and there is a chance of falling into a known opening traps. The book “Game changer” mentioned the game above as an example (note, that it’s one of not that many games lost by AlphaZero).
-
To make learning techniques practical training time should be reasonably small and an algorithm should allow some form of retraining to take into account new data. This question is tightly connected with whether provide an existing human knowledge for an algorithm or not. In case of Neo it’s an important way of speeding up training (otherwise it would be tremendously slow, since one has to execute not optimal queries over and over again), but AlphaZero avoids that, because prise of training is smaller and eliminating existing knowledge allows discovering new tactics.
-
The ability to debug and explain decisions made in self-learned way is itself a subject of research and not straightforward at all.
Summary
To repeat Richard Hamming again, learning algorithms is a topic one cannot afford to ignore, including its application in databases. Obviously the approach of predicting an execution plan efficiency is not the only way of doing query optimization. Another interesting example is a learning algorithm that optimizes not a plan itself, but a set of plan hints that could steer query optimizer in one or another way. And I’m sure there are many others exist, taking into account general nature of the question, when the same ideas could be applied for completely different set of problems.
Thanks to authors of all mentioned papers and books for sharing those fascinating insights!