Compare incomparable: PostgreSQL vs Mysql vs Mongodb
29 Dec 2015As such, there’s really no “standard” benchmark that will inform you about the best technology to use for your application. Only your requirements, your data, and your infrastructure can tell you what you need to know.
NoSql is everywhere and we can’t escape from it (although I can’t say we want to escape). Let’s leave the question about reasons outside this text, and just note one thing - this trend isn’t related only to new or existing NoSql solutions. It has another side, namely the schema-less data support in traditional relational databases. It’s amazing how many possibilities hiding at the edge of the relational model and everything else. But of course there is a balance that you should find for your specific data. It can’t be easy, first of all because it’s required to compare incomparable things, e.g. performance of a NoSql solution and traditional database. Here in this post I’ll make such attempt and show the comparison of jsonb in PostgreSQL, json in Mysql and bson in Mongodb.
What the hell is going on here?
Breaking news:
- PostgreSQL 9.4 - a new data type
jsonbwith slightly extended support in the upcoming release PostgreSQL 9.5 - Mysql 5.7.7 - a new data type
json
and several other examples (I’ll talk about them later). Of course these data types supposed to be binary, which means great performance. Base functionality is equal across the implementations because it’s just obvious CRUD. And what is the oldest and almost cave desire in this situation? Right, performance benchmarks! PostgreSQL and Mysql were choosen because they have quite similar implementation of json support, Mongodb - as a veteran of NoSql. An EnterpriseDB research is slightly outdated, but we can use it as a first step for the road of a thousand li. A final goal is not to display the performance in artificial environment, but to give a neutral evaluation and to get a feedback.
Some details and configurations
The pg_nosql_benchmark from EnterpriseDB suggests an obvious approach - first of all the required amount of records must be generated using different kinds of
data and some random fluctuations. This amount of data will be saved into the database, and we will perform several kinds of queries over it.
pg_nosql_benchmark doesn’t have any functional to work with Mysql, so I had to implement it similar to PostgreSQL.
There is only one tricky thing with Mysql - it doesn’t support json indexing directly, it’s required to create virtual columns and create index on them.
Speaking of details, there was one strange thing in pg_nosql_benchmark. I figured out that few types of generated records
were beyond the 4096 bytes limit for mongo shell, which means these records were
just dropped out. As a dirty hack for that we can perform the inserts from a js file (and btw, that file must be splitted into the series of chunks
less than 2GB).
Besides, there are some unnecessary time expenses, related to shell client, authentication and so on. To estimate and exclude them I have to perform corresponding amount of “no-op” queries for all databases (but they’re actually pretty small).
After all modifications above I’ve performed measurements for the following cases:
- PostgreSQL 9.5 beta1, gin
- PostgreSQL 9.5 beta1, jsonb_path_ops
- PostgreSQL 9.5 beta1, jsquery
- Mysql 5.7.9
- Mongodb 3.2.0 storage engine WiredTiger
- Mongodb 3.2.0 storage engie MMAPv1
Each of them was tested on a separate m4.xlarge amazon instance with the ubuntu 14.04 x64 and default configurations,
all tests were performed for 1000000 records. And you shouldn’t forget about the instructions for the jsquery -
bison, flex, libpq-dev and postgresql-server-dev-9.5 must be installed. All results were saved in json file,
we can visualize them easily using matplotlib (see here).
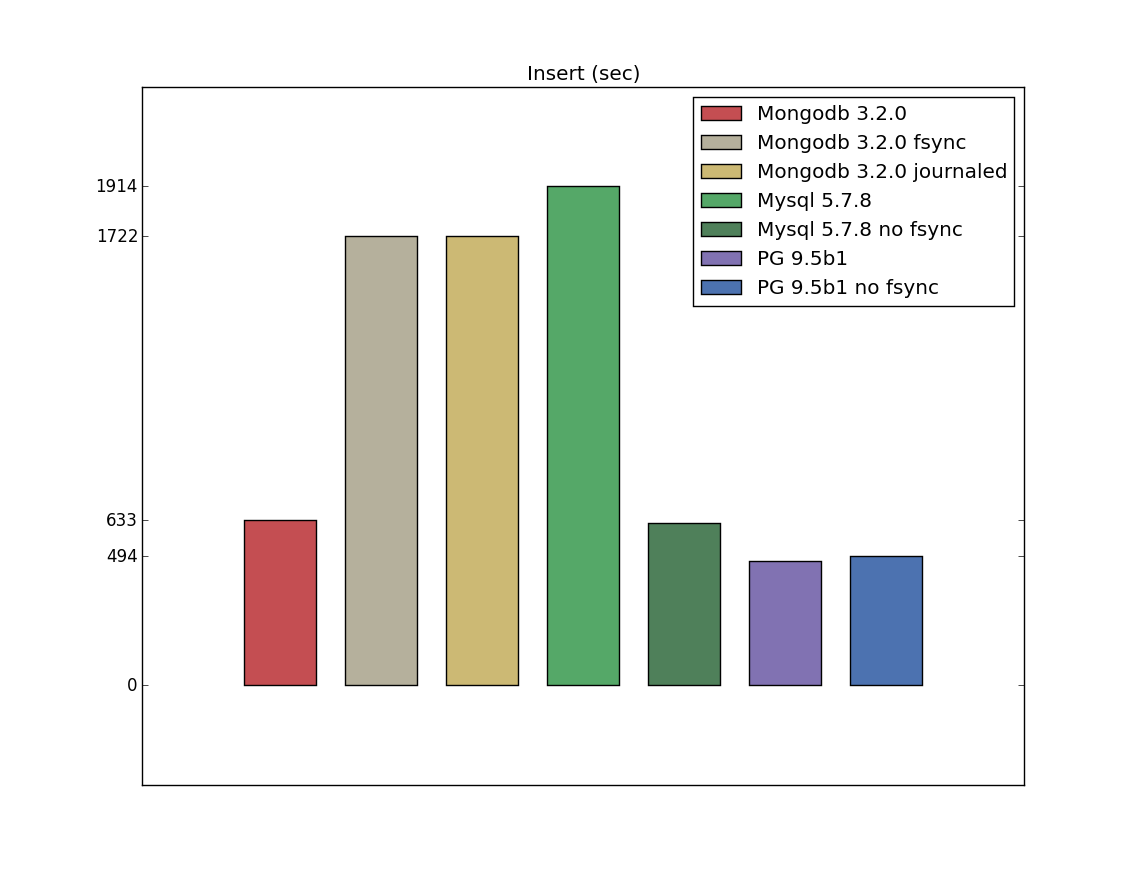
Besides that there was a concern about durability. To take this into account I made few specific configurations (imho some of them are real, but some of them are quite theoretical, because I don’t think someone will use them for production systems):
- Mongodb 3.2.0 journaled (writeConcern j: true)
- Mongodb 3.2.0 fsync (transaction_sync=(enabled=true,method=fsync))
- PostgreSQL 9.5 beta 1, no fsync (fsync=off)
- Mysql 5.7.9, no fsync (innodb_flush_method=nosync)
Results
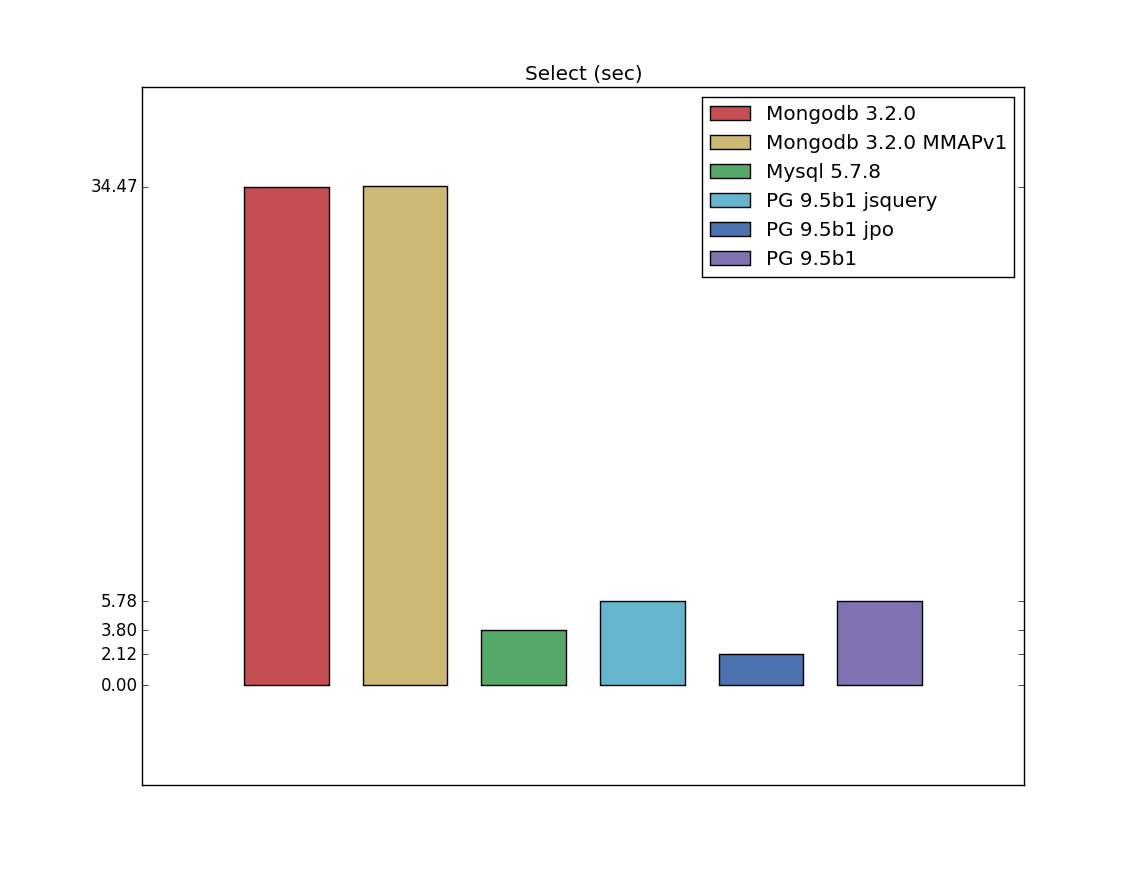
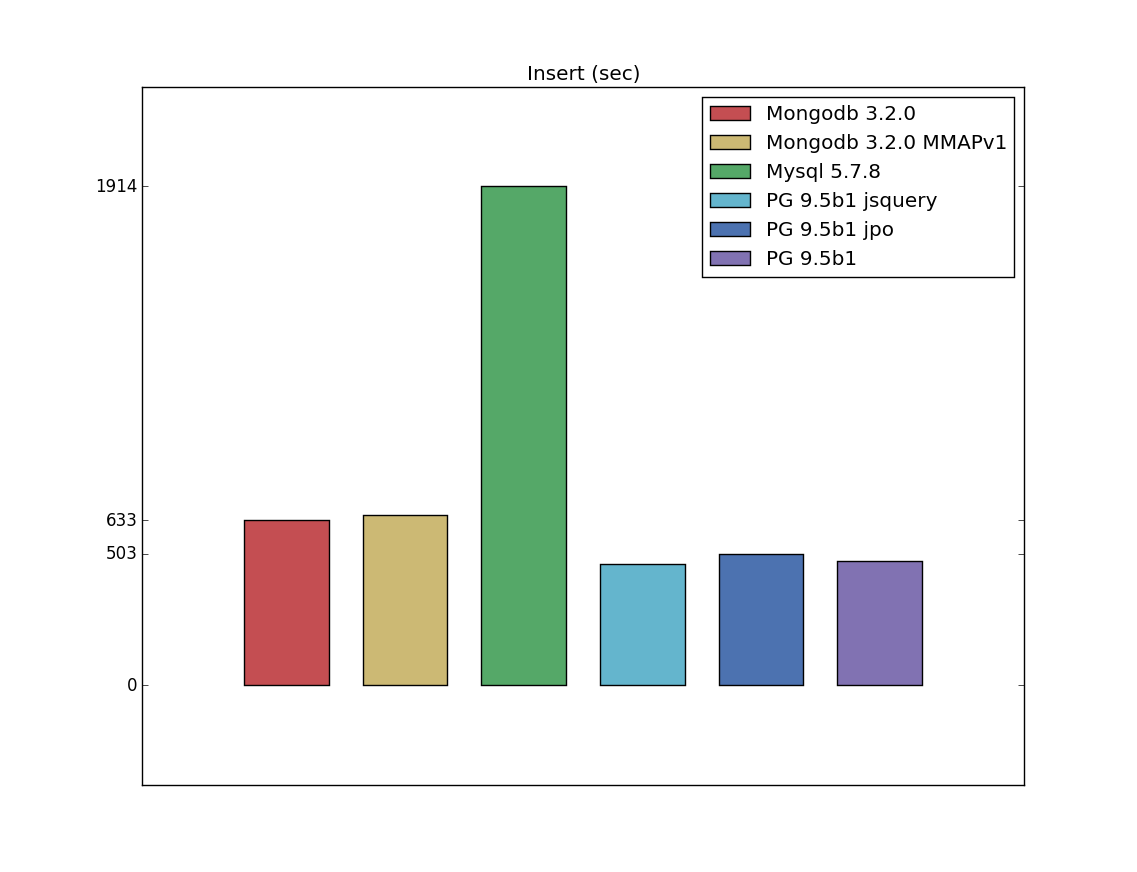
All charts presented in seconds (if they related to the time of query execution) or mb (if they related to the size of relation/index). Thus, for all charts the smaller value is better.
Select
Insert
Insert with configurations
Update
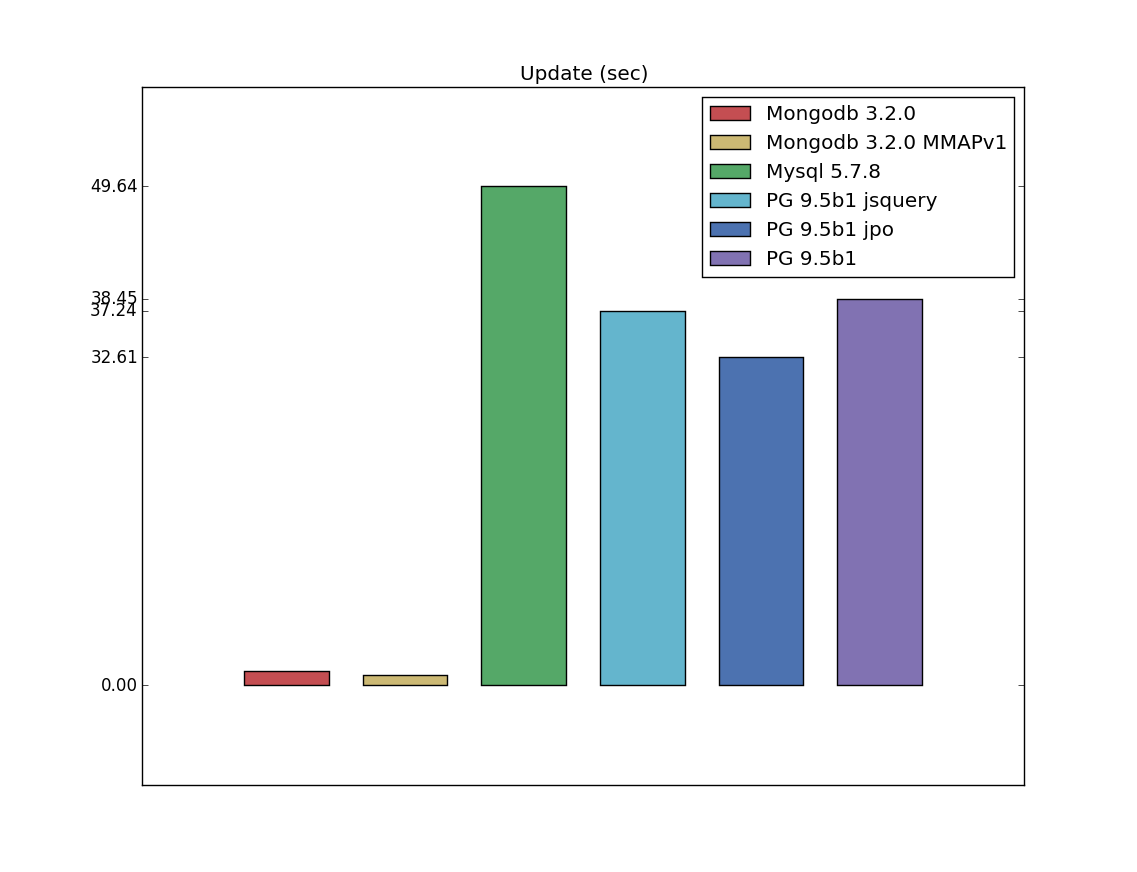
Update is another difference between my benchmarks and pg_nosql_benchmark. It can bee seen, that Mongodb is an obvious
leader here - mostly because of PostgreSQL and Mysql restrictions, I guess, when to update one value you must override an entire field.
Update with configurations
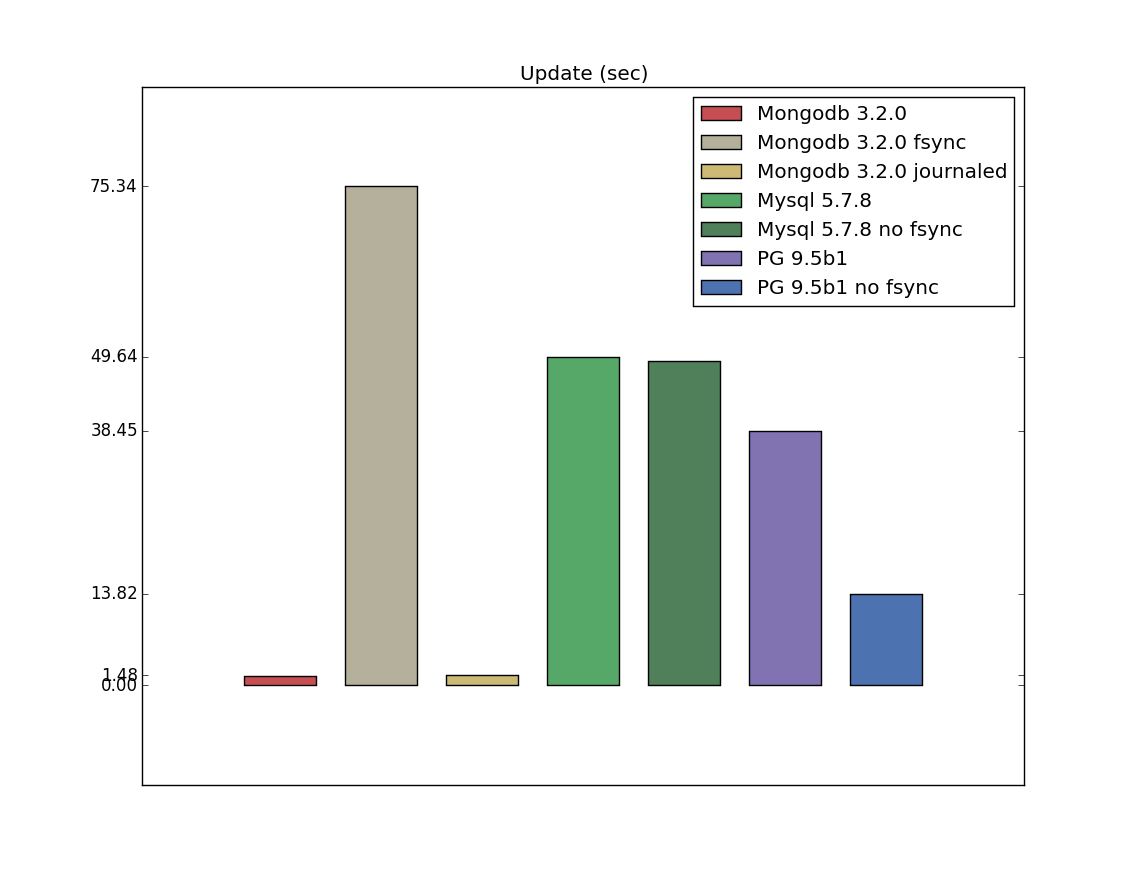
As you can guess from documentation and this answer,
writeConcern j:true is the highest possible transaction durability level (on a single server),
that should be equal to configuration with fsync.
I’m not sure about durability, but fsync is definitely slower for update operations here.
Table/index size
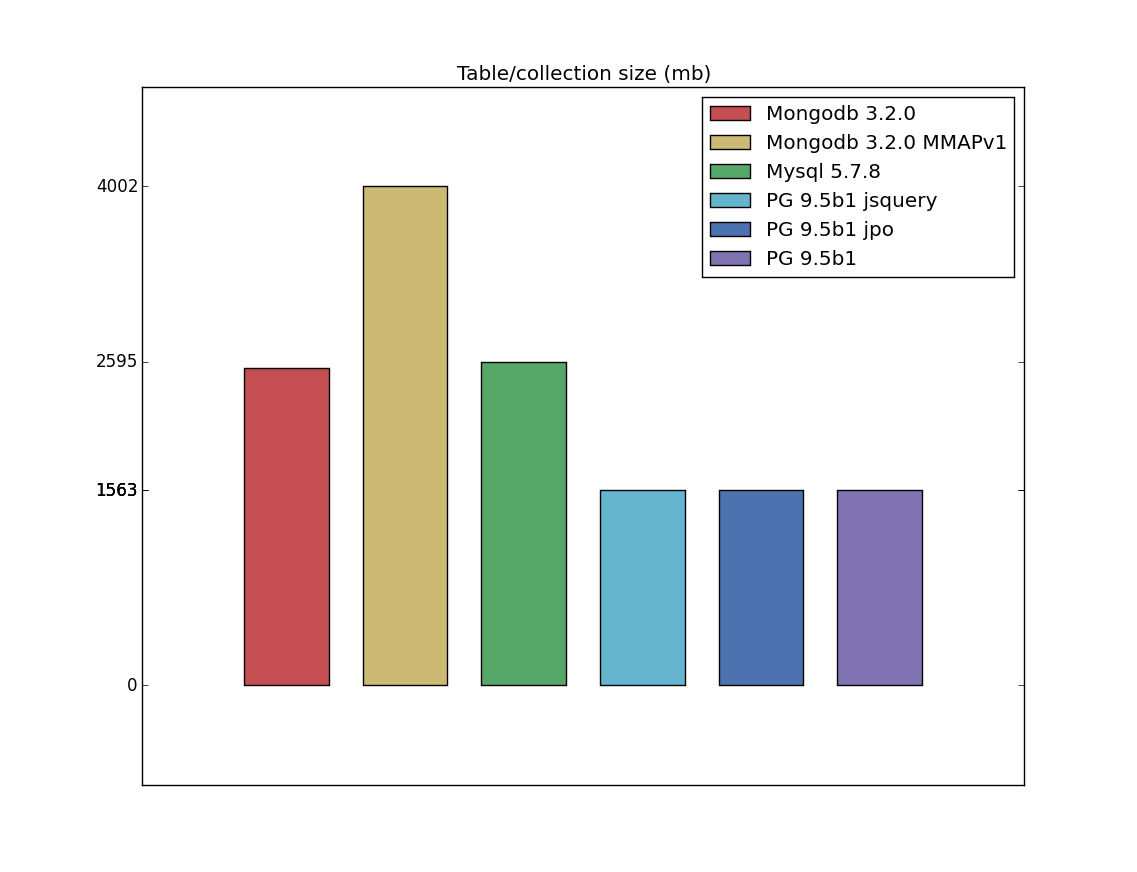
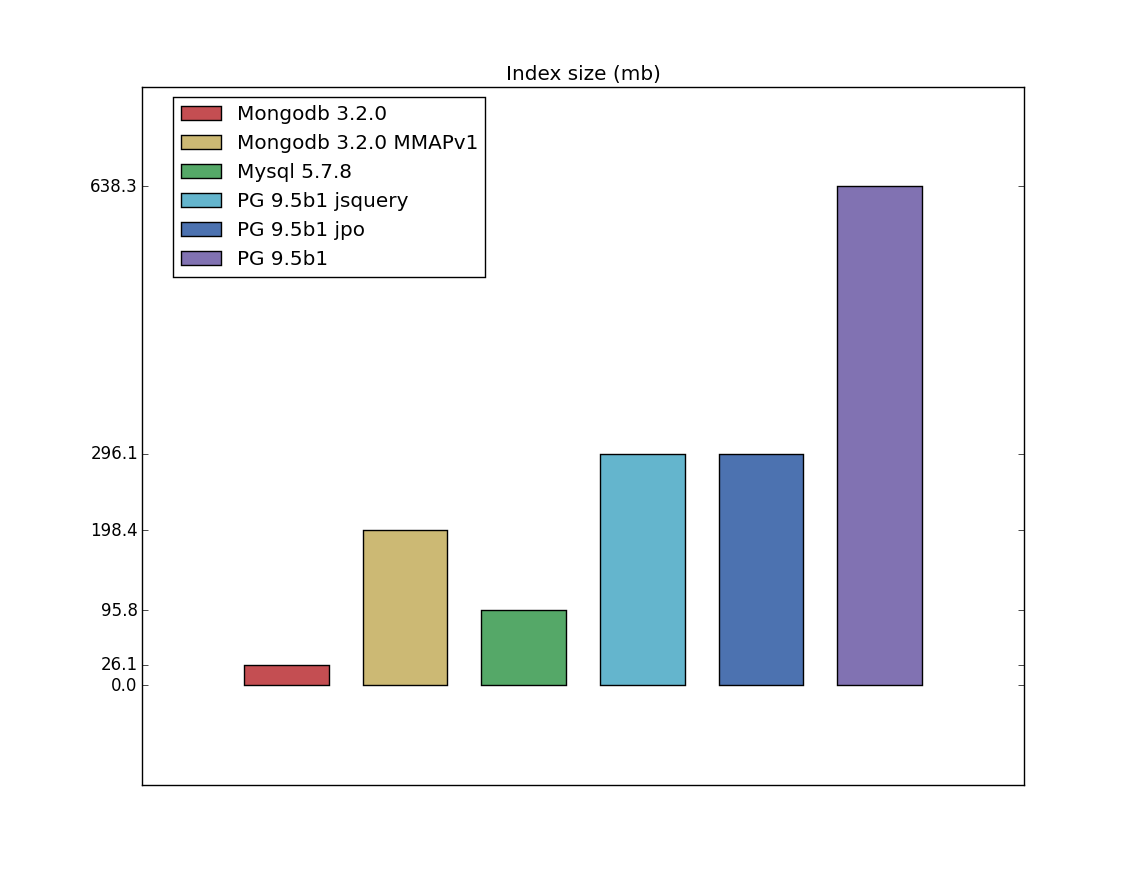
I have a bad feeling about this
Performance measurement is a dangerous field especially in this case. Everything described above can’t be a completed benchmark, it’s just a first step to understand current situation. We’re working now on ycsb tests to make more finished measurements, and if we’ll get lucky we’ll compare the performance of cluster configurations.
PgConf.Russia 2016
It looks like I’ll participate in the PgConf.Russia this year, so if you’re interested in this subject - welcome.